
LEX
- Lex is officially known as a “Lexical Analyser”.
- Its main job is to break up an input stream into more usable elements. Or in, other words, to identify the “interesting bits” in a text file.
- For example, if you are writing a compiler for the C programming language, the symbols { } ( ); all have significance on their own.
- The letter a usually appears as part of a keyword or variable name, and is not interesting on its own.
- Instead, we are interested in the whole word. Spaces and newlines are completely uninteresting, and we want to ignore them completely, unless they appear within quotes “like this”
- All of these things are handled by the Lexical Analyser.
- A tool widely used to specify lexical analyzers for a variety of languages
- We refer to the tool as Lex compiler, and to its input specification as the Lex language.

Lex specifications:
A Lex program (the .l file) consists of three parts:
declarations
%%
translation rules
%%
YACC
- Yacc is officially known as a “parser”.
- It’s job is to analyse the structure of the input stream, and operate of the “big picture”.
- In the course of it’s normal work, the parser also verifies that the input is syntactically sound.
- Consider again the example of a C-compiler. In the C-language, a word can be a function name or a variable, depending on whether it is followed by a (or a = There should be exactly one } for each { in the program.
- YACC stands for “Yet another Compiler Compiler”. This is because this kind of analysis of text files is normally associated with writing compilers.

How does this yacc works?
- yacc is designed for use with C code and generates a parser written in C.
- The parser is configured for use in conjunction with a lex-generated scanner and relies on standard shared features (token types, yylval, etc.) and calls the function yylex as a scanner coroutine.
- You provide a grammar specification file, which is traditionally named using a .y extension.
- You invoke yacc on the .y file and it creates the y.tab.h and y.tab.c files containing a thousand or so lines of intense C code that implements an efficient LALR (1) parser for your grammar, including the code for the actions you specified.
- The file provides an extern function yyparse.y that will attempt to successfully parse a valid sentence.
- You compile that C file normally, link with the rest of your code, and you have a parser! By default, the parser reads from stdin and writes to stdout, just like a lex-generated scanner does.
Difference between LEX and YACC
- Lex is used to split the text into a list of tokens, what text become token can be specified using regular expression in lex file.
- Yacc is used to give some structure to those tokens. For example in Programming languages, we have assignment statements like int a = 1 + 2; and i want to make sure that the left hand side of ‘=’ be an identifier and the right side be an expression [it could be more complex than this]. This can be coded using a CFG rule and this is what you specify in yacc file and this you cannot do using lex (lexcannot handle recursive languages).
- A typical application of lex and yacc is for implementing programming languages.
- Lex tokenizes the input, breaking it up into keywords, constants, punctuation, etc.
- Yacc then implements the actual computer language; recognizing a for statement, for instance, or a function definition.
- Lex and yacc are normally used together. This is how you usually construct an application using both:
- Input Stream (characters) -> Lex (tokens) -> Yacc (Abstract Syntax Tree) -> Your Application
Instruction Formats
These formats are classified by length in bytes, use of the base registers, and object code format. The five instruction classes of use to the general user are listed below.
Format Length Use
Name in bytes
RR 2 Register to register transfers.
RS 4 Register to storage and register from storage
RX 4 Register to indexed storage and register from indexed storage
SI 4 Storage immediate
SS 6 Storage–to–Storage. These have two variants,
each of which we shall discuss soon.
Compiler Design – Phases of Compiler
The compilation process is a sequence of various phases. Each phase takes input from its previous stage, has its own representation of source program, and feeds its output to the next phase of the compiler. Let us understand the phases of a compiler.
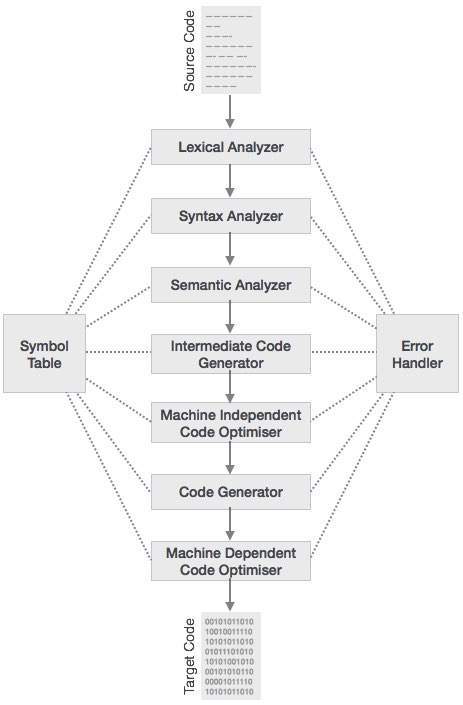
Lexical Analysis
The first phase of scanner works as a text scanner. This phase scans the source code as a stream of characters and converts it into meaningful lexemes. Lexical analyzer represents these lexemes in the form of tokens as:
<token-name, attribute-value>
Syntax Analysis
The next phase is called the syntax analysis or parsing. It takes the token produced by lexical analysis as input and generates a parse tree (or syntax tree). In this phase, token arrangements are checked against the source code grammar, i.e. the parser checks if the expression made by the tokens is syntactically correct.
Semantic Analysis
Semantic analysis checks whether the parse tree constructed follows the rules of language. For example, assignment of values is between compatible data types, and adding string to an integer. Also, the semantic analyzer keeps track of identifiers, their types and expressions; whether identifiers are declared before use or not etc. The semantic analyzer produces an annotated syntax tree as an output.
Intermediate Code Generation
After semantic analysis the compiler generates an intermediate code of the source code for the target machine. It represents a program for some abstract machine. It is in between the high-level language and the machine language. This intermediate code should be generated in such a way that it makes it easier to be translated into the target machine code.
Code Optimization
The next phase does code optimization of the intermediate code. Optimization can be assumed as something that removes unnecessary code lines, and arranges the sequence of statements in order to speed up the program execution without wasting resources (CPU, memory).
Code Generation
In this phase, the code generator takes the optimized representation of the intermediate code and maps it to the target machine language. The code generator translates the intermediate code into a sequence of (generally) re-locatable machine code. Sequence of instructions of machine code performs the task as the intermediate code would do.
Symbol Table
It is a data-structure maintained throughout all the phases of a compiler. All the identifier’s names along with their types are stored here. The symbol table makes it easier for the compiler to quickly search the identifier record and retrieve it. The symbol table is also used

I loved as much as you’ll receive carried out right here. The sketch iss tasteful, your authored subject matter stylish.
nonetheless, you command get got an shakiness over that you wish be delivering thee following.
unwell unquestionably come more formerly again since exactly
thhe same nearly very often inside case you shield this increase.
LikeLike